MAC下安装Tesseract

最近项目中需要使用到OCR识别镂空数字,于是开始学习Tesseract https://github.com/tesseract-ocr/tesseract
接下来记录一下我在安装和使用过程当中的遇到的坑和学习的过程,本文主要记录了Mac下安装tesseract的过程。
环境:
JDK 1.8
MACOSX 10.14.4
Tesseract 安装
首先是Tesseract的安装,目前百度 mac安装Tesseract时,大多是都是推荐使用HomeBrew进行安装,本人也是推荐在mac中
使用HomeBrew(国内镜像安装 https://mirrors.tuna.tsinghua.edu.cn/help/homebrew/),但是使用HomeBrew安装 tesseract只能使用识别功能不能进行训练,经过搜索后发现目前已经不支持 使用“
brew install --with-training-tools tesseract
”需要进行编译安装,下面是编译安装流程:
1. 下载依赖
# Packages which are always needed.
brew install automake autoconf libtool
brew install pkgconfig
brew install icu4c
brew install leptonica
# Packages required for training tools.
brew install pango
# Optional packages for extra features.
brew install libarchive
# Optional package for builds using g++.
brew install gcc
2. 下载tesseract-4.1.1
这里我选择的时候4.1.1 release 版本
https://github.com/tesseract-ocr/tesseract/releases
3. 编译安装
将下载的tesseract解压,然后使用terminal进入此文件夹
cd tesseract-4.1.1
./autogen.sh
mkdir build
cd build
# Optionally add CXX=g++-8 to the configure command if you really want to use a different compiler.
../configure PKG_CONFIG_PATH=/usr/local/opt/icu4c/lib/pkgconfig:/usr/local/opt/libarchive/lib/pkgconfig:/usr/local/opt/libffi/lib/pkgconfig
make -j
# Optionally install Tesseract.
sudo make install
# Optionally build and install training tools.
make training
sudo make training-install
4. 测试
tesseract -v
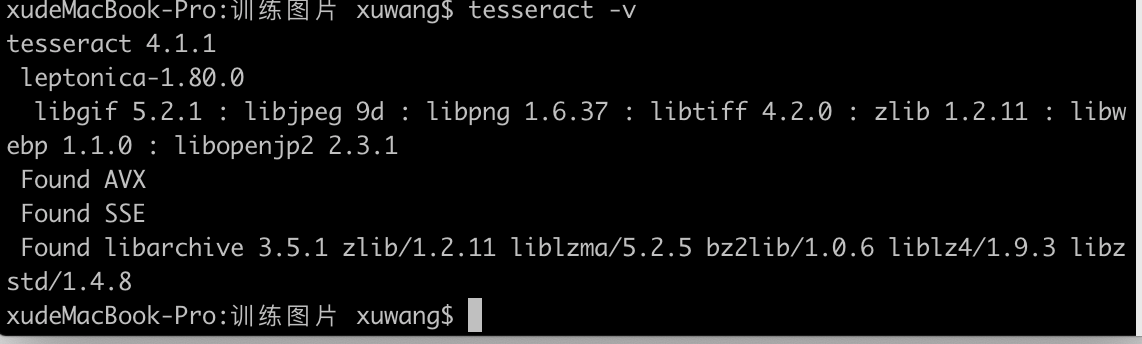
unicharset_extractor -v
(注意unicharset_extractor -v 不提示找不到此命令时,才说明已经安装了训练功能)

{{ commentCount }}条评论
{{ cmt.username }}
{{ cmt.content }}
{{ cmt.commentDate | formatDate('YYYY.MM.DD hh:mm') }}