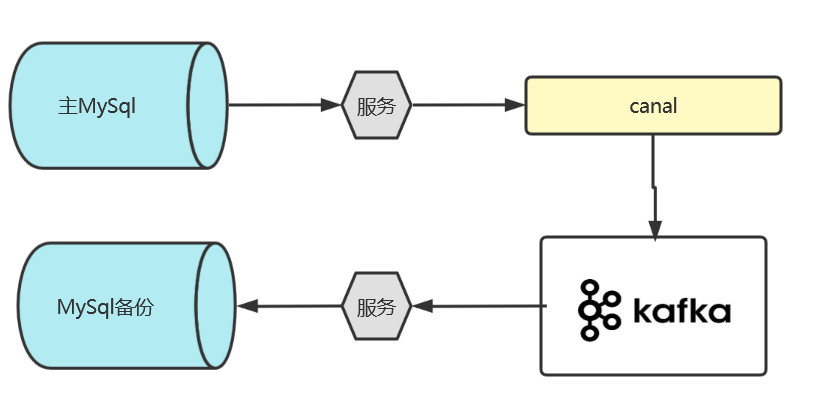
使用Canal实现增量式数据同步

整体流程
首先是主MySql作为一个核心的数据库,canal中也只需要配置且仅配置该核心数据库即可,而springboot项目作为一个服务用来维系Mysql和canal。但因为canal只是作为一个通道存在,它的本质是监听,所以它需要连接到Kafka,经过消息中间件做一个异步的备份写入,其中,负责写入的springboot项目作为一个服务用来维系Kafka和备份Mysql数据库。当然,MySql备份不是固定的,因为消息中间件的存在,备份数据库和主数据库已经可以被隔离开来,因此,当主数据库是MySql的时候,备份数据库完全可以是HBase或者Oracle。
一:MySql环境
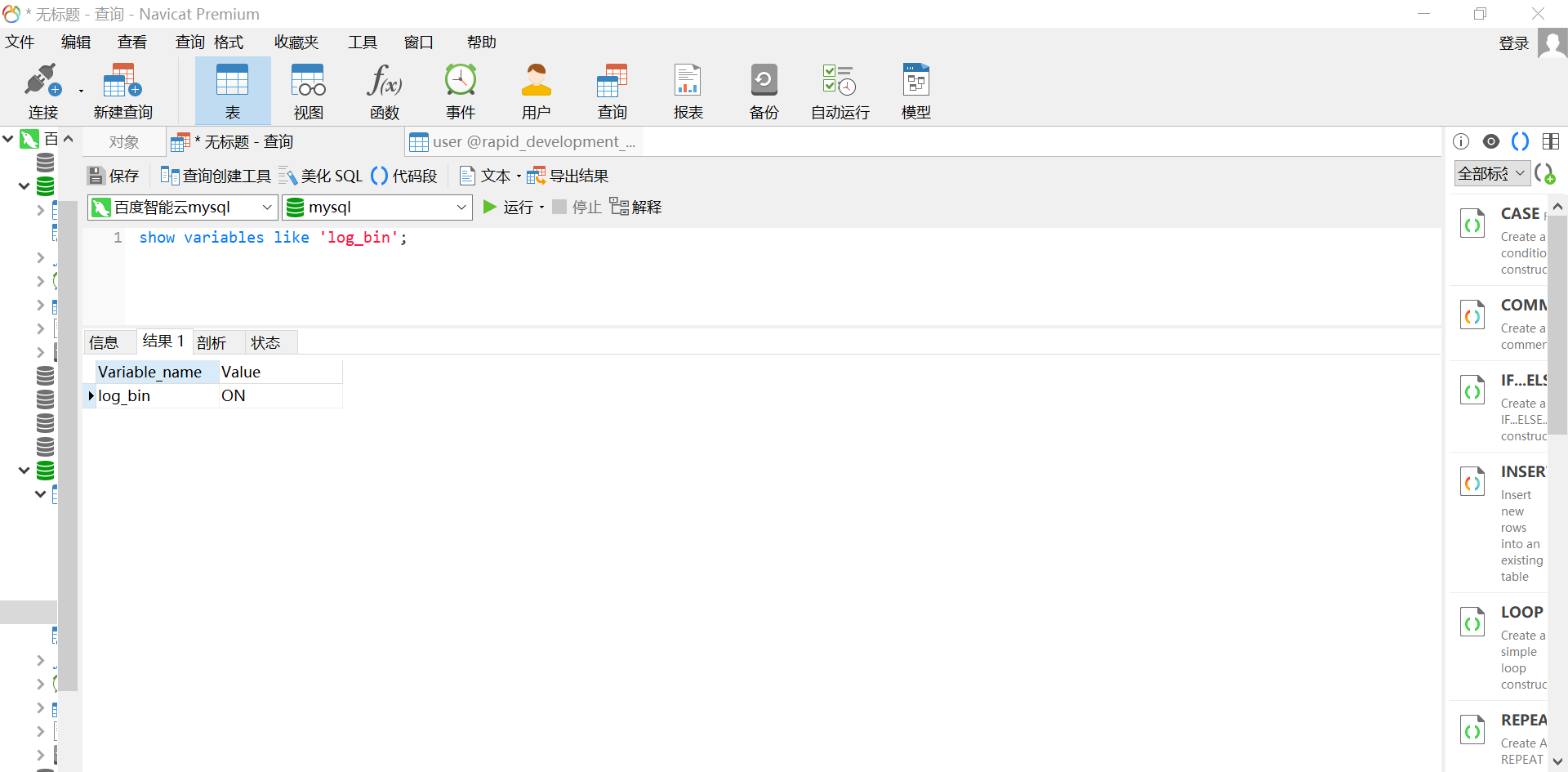
首先要让mysql开启binlog,使用show variables like 'log_bin'; 可以查看,要求该选项必须为ON
开启方法:在my.cnf中追加如下配置
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
接着创建一个用户并授权用来连接canal
CREATE USER canal IDENTIFIED BY 'Canal@123456';
GRANT SELECT,INSERT,UPDATE,DELETE, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
重启mysql使配置生效
二:安装Canal
github:alibaba/canal: 阿里巴巴 MySQL binlog 增量订阅&消费组件 (github.com)
简介
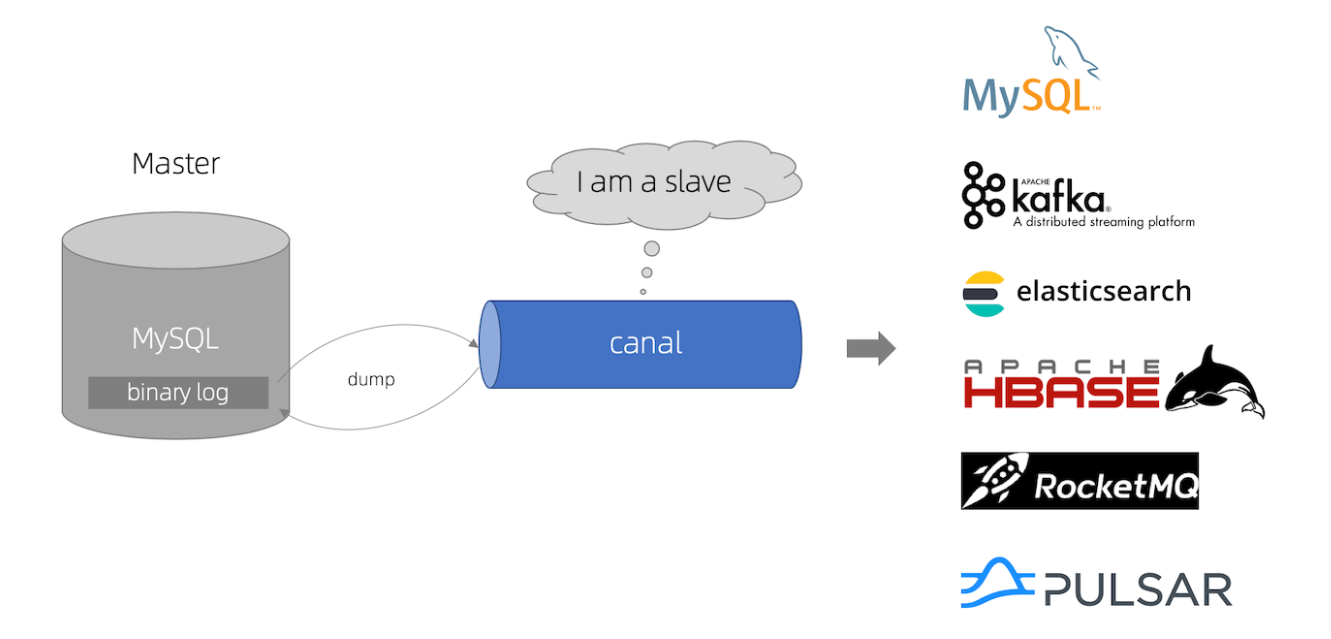
canal 译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
这里我下载的是1.14稳定版:Release v1.1.4 · alibaba/canal (github.com)
将tar包下载完之后解压,修改canal.properties
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111 #canal的端口
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal #client中连接的用户名
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458 #密码
关于canal.passwd如何获取新的加密密码,在1.1.4版本中,可以去canal源码的canal.protocl模块下找一个叫做SecurityUtil的工具,调用其中的scrambleGenPass方法来获取新的密码。
去 canal.deployer-1.1.4\conf\example下找 instance.properties文件
## mysql serverId
canal.instance.mysql.slaveId = 1234 #该条默认在最上方被注释着,需提前打开
#position info,需要改成自己的数据库信息
canal.instance.master.address = 127.0.0.1:3306
canal.instance.master.journal.name =
canal.instance.master.position =
canal.instance.master.timestamp =
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#username/password,需要改成自己的数据库信息
canal.instance.dbUsername = canal #这里就是前面建立的mysql用户
canal.instance.dbPassword = canal
canal.instance.defaultDatabaseName =
canal.instance.connectionCharset = UTF-8
#table regex 白名单
canal.instance.filter.regex = #可以直接空着,或者是.\*\\\\..\*表示全部
# table black regex 黑名单
canal.instance.filter.black.regex= #黑名单,test\\..*,禁用掉test库的全部
黑白名单常见例子
1. 所有表:.* or .*\\..*
2. canal schema下所有表: canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal\\.test1
5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)
然后可以去 bin路径下找启动脚本,这里我是windows环境,因此启动bat脚本,如果windows启动报错,则将如下一条从脚本中删除。如果是Linux直接运行startup.sh即可,无需修改脚本,然后可以开ps -ef | grep canal看一下是否启动成功。
重新启动,启动成功后会看到监听9090的提示,但实际上canal我们需要连接的是它的11111端口,产生如下图所示结果即正确。
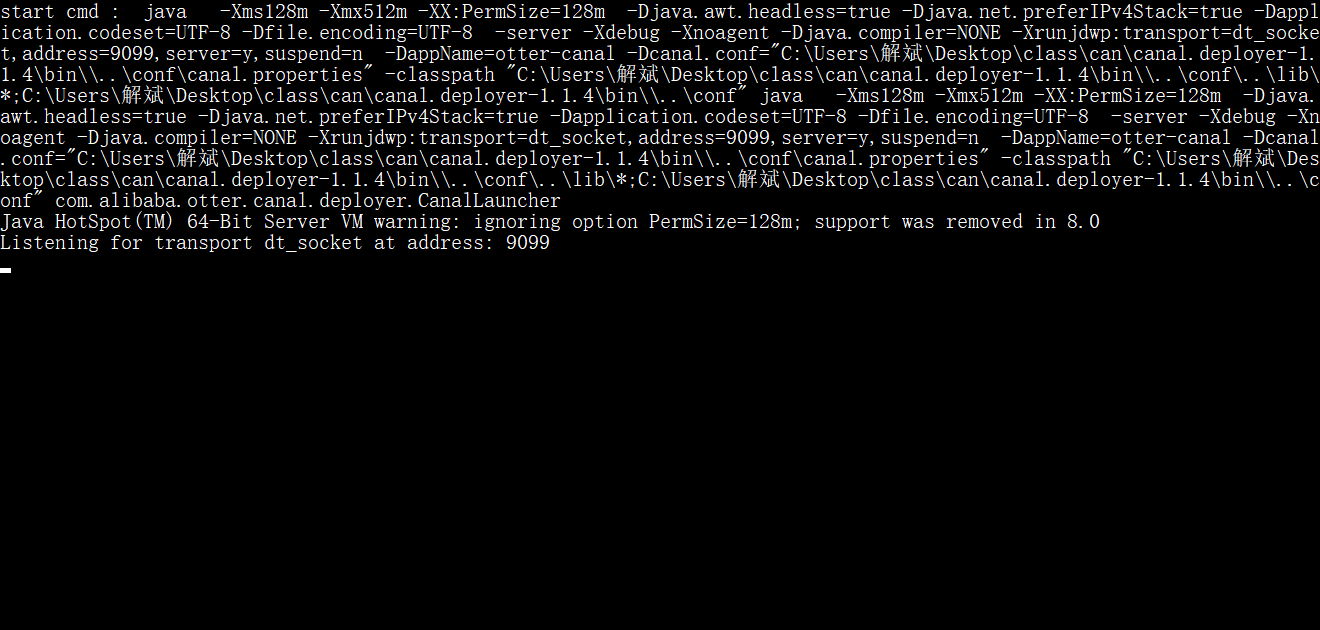
三:SpringBoot中启用
pom.xml
<!-- canal.client 数据同步-->
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.protocol</artifactId>
<version>1.1.4</version>
</dependency>
<!--log4j-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
<scope>test</scope>
</dependency>
CanalClient.java
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException;
import org.apache.commons.dbutils.DbUtils;
import org.apache.commons.dbutils.QueryRunner;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import javax.sql.DataSource;
import java.net.InetSocketAddress;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
@Component
public class CanalClient {
Logger logger = LoggerFactory.getLogger(CanalClient.class);
//sql队列
private Queue<String> SQL_QUEUE = new ConcurrentLinkedQueue<>();
@Resource
private DataSource dataSource;
/**
* canal入库方法
*/
public void run() {
/*canal服务器地址,以及开启的端口号,如果是跟我一样本地起的canal脚本,则不需要更改任何内容*/
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1",
11111), "example", "", "");
int batchSize = 1000;
try {
while (true) {
logger.info("-------------canal开始连接-------------");
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
} catch (Exception e) {
logger.info("-------------canal连接失败,五分钟后尝试重新连接-------------");
try {
Thread.sleep(300000);
} catch (InterruptedException e1) {
logger.error(e1.getMessage());
}
}
logger.info("-------------canal连接成功-------------");
break;
}
while (true) try {
/*从master拉取数据batchSize条记录*/
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
Thread.sleep(10000);
} else {
dataHandle(message.getEntries());
}
/*提交ack确认*/
connector.ack(batchId);
/*设置队列sql语句执行最大值*/
if (SQL_QUEUE.size() >= 1) {
executeQueueSql();
}
} catch (Exception e) {
e.printStackTrace();
logger.error("canal入库方法" + e.getMessage());
}
} finally {
connector.disconnect();
}
}
/**
* 模拟执行队列里面的sql语句
*/
public void executeQueueSql() {
int size = SQL_QUEUE.size();
for (int i = 0; i < size; i++) {
String sql = SQL_QUEUE.poll();
System.out.println("[sql]----> " + sql);
this.execute(sql.toString());
}
}
/**
* 数据处理
*
* @param entrys
*/
private void dataHandle(List<Entry> entrys) throws
InvalidProtocolBufferException {
for (Entry entry : entrys) {
if (EntryType.ROWDATA == entry.getEntryType()) {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
EventType eventType = rowChange.getEventType();
if (eventType == EventType.DELETE) {
saveDeleteSql(entry);
} else if (eventType == EventType.UPDATE) {
saveUpdateSql(entry);
} else if (eventType == EventType.INSERT) {
saveInsertSql(entry);
}
}
}
}
/**
* 保存更新语句
*
* @param entry
*/
private void saveUpdateSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> newColumnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("update " +
entry.getHeader().getTableName() + " set ");
for (int i = 0; i < newColumnList.size(); i++) {
sql.append(" " + newColumnList.get(i).getName()
+ " = '" + newColumnList.get(i).getValue() + "'");
if (i != newColumnList.size() - 1) {
sql.append(",");
}
}
sql.append(" where ");
List<Column> oldColumnList = rowData.getBeforeColumnsList();
for (Column column : oldColumnList) {
if (column.getIsKey()) {
//暂时只支持单一主键
sql.append(column.getName() + "= ''" + column.getValue() +"'");
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* 保存删除语句
*
* @param entry
*/
private void saveDeleteSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> columnList = rowData.getBeforeColumnsList();
StringBuffer sql = new StringBuffer("delete from " +
entry.getHeader().getTableName() + " where ");
for (Column column : columnList) {
if (column.getIsKey()) {
//暂时只支持单一主键
sql.append(column.getName() + "= '" + column.getValue() +"'");
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* 保存插入语句
*
* @param entry
*/
private void saveInsertSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> columnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("insert into " +
entry.getHeader().getTableName() + " (");
for (int i = 0; i < columnList.size(); i++) {
sql.append(columnList.get(i).getName());
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(") VALUES (");
for (int i = 0; i < columnList.size(); i++) {
sql.append("'" + columnList.get(i).getValue() + "'");
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(")");
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* ⼊库
* @param sql
*/
public void execute(String sql) {
Connection con = null;
try {
if(null == sql) return;
con = dataSource.getConnection();
QueryRunner qr = new QueryRunner();
int row = qr.execute(con, sql);
System.out.println("update: "+ row);
} catch (SQLException e) {
e.printStackTrace();
} finally {
DbUtils.closeQuietly(con);
}
}
}
启动类:
@SpringBootApplication
@MapperScan("com.jt.mapper")
@EnableAsync
public class ServiceMain implements CommandLineRunner{
@Resource
private CanalClient canalClient;
public static void main(String[] args) {
SpringApplication.run(ServiceMain.class, args);
}
//开启运行canal备份监听
@Override
public void run(String... strings) throws Exception {
/*启动canal客户端监听*/
canalClient.run();
}
}
运行之后如果正确连通会提示canal连接正确,这个时候,如果被监听的数据库发生数据上的变化,那么canalClient就会根据binlog进行同步提示。下面提示的报错时因为数据库有一个字段为空所导致的。
四:安装Kafka
但光是成功使用了canal还是不够的,一般canal就只是充当一个监听管道,由它将监听到sql传递给消息中间,接着在另一端服务器上启动一个消费者,消费者时刻侦听对应的中间件topic,然后异步的将数据写入备份的数据库,这样一来,无论我是将它备份在mysql还是其他的hbase,通过该操作都能实现。
Kafka官网:Apache Kafka
首先下载kafka,这里我下载的是0.11.0版本

将安装包上传到服务器,这里我新建了/usr/local/software文件夹,并将安装包拖拽到当前文件夹下
1)解压安装包
tar -zxvf kafka_2.11-0.11.0.0.tgz
2)修改解压后的文件夹名称
mv kafka_2.11-0.11.0.0.tgz kafka
3)在/usr/local/software/kafka下建立logs和data文件夹
mkdir logs && mkdir data
4)修改配置文件
cd config
vi server.properties
修改配置
#broker 的全局唯一编号,不能重复
broker.id=0
#删除 topic 功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行数据存放的路径
log.dirs=/usr/local/software/kafka/data
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置对外开放的ip,这个是java内部使用api时填写的地址,如果不配置则外部api无法调用
advertised.listeners=PLAINTEXT://192.168.84.136:9092
#这里监听地址0.0表示任意人都可访问
listeners=PLAINTEXT://0.0.0.0:9092
kafka集成了zookeeper,等会儿直接开启
zookeeper.connect=localhost:2181 #这里是默认配置,无需修改
如果是集群启动,中间加逗号隔开
zookeeper.connect=192.168.132.1:2181,192.168.132.2:2181,192.168.132.3:2181
5) 配置环境变量
vi /etc/profile
内容如下:
#KAFKA_HOME
export KAFKA_HOME=/usr/local/software/kafka
export PATH=$PATH:$KAFKA_HOME/bin
使用 source /etc/profile 更新一下
6) 启动,如果是集群启动的话那就按照上面的配置配置多台即可(这里-daemon是守护进程的意思)
- 首先是启动zookeeper
./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
- 然后是启动kafka
./bin/kafka-server-start.sh -daemon config/server.properties
可以在当前路径下使用jps命令来查看开启的kafka,其中QuorumPeerMain代表zookeeper已经开启了

7)关闭的操作
./bin/kafka-server-stop.sh stop
五:SpringBoot整合Kafka
5.1 版本配置
参考网址:https://spring.io/projects/spring-kafka#overview
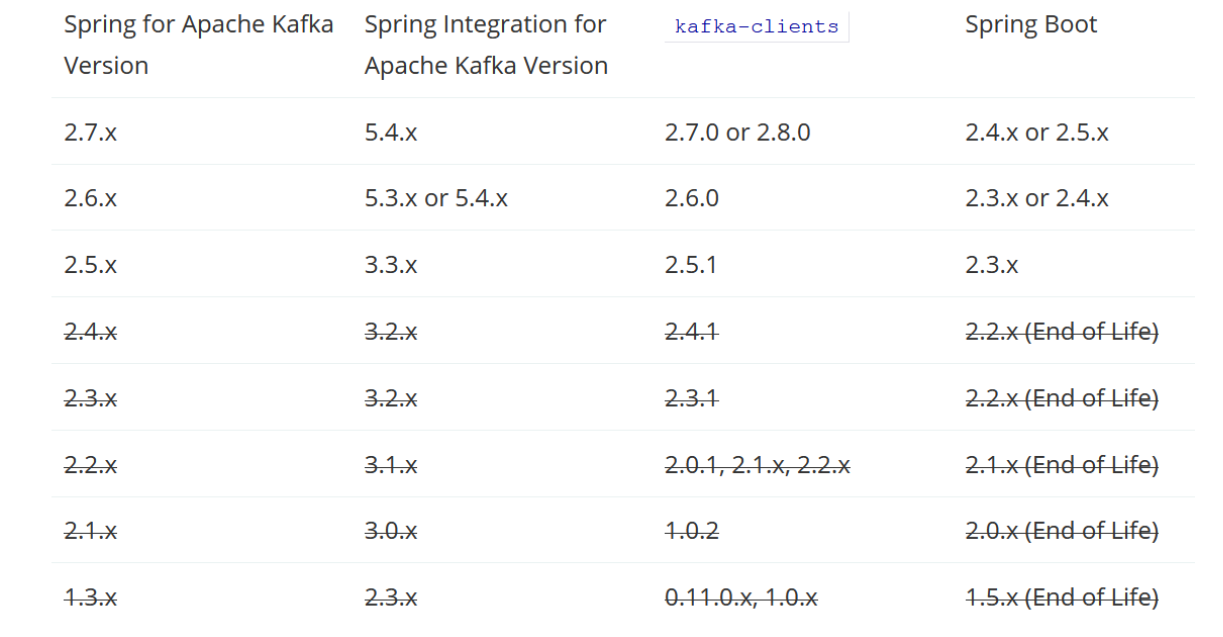
我这里默认使用了springboot2.5.x的版本,其对应的kafka版本是2.7.0或者2.8.0,kafka高版本可以向下兼容,因此我这里没有动boot的版本,而是选择了升级kafka版本到2.8.0
5.2 环境搭建
创建一个springboot项目,引入web即可,lombok可以不引入
5.2.1 pom.xml
重点引入
<!--引入kafak和spring整合的jar,这里不加版本号的话2.5的boot默认是2.7.0-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!--这里手动引入2.8.0版本-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.0</version>
</dependency>
完整配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.6</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.sb</groupId>
<artifactId>kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>kafka</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!--引入kafak和spring整合的jar,这里不加版本号的话默认是2.7.0-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--这里手动引入2.8.0版本-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.44</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
5.2.2 application.yaml
server:
port: 8080
spring:
kafka:
bootstrap-servers: 101.34.6.176:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: test01 #组名
enable-auto-commit: true #开启自动提交offset
auto-commit-interval: 1000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
#auto-offset-reset: earliest 重置offset
5.2.3 Controller中编写Producer
KafkaController
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@RestController
public class KafkaController {
@Resource
private KafkaTemplate<String,String> kafkaTemplate;
//消息发送
@GetMapping("/kafka/send")
public String send(String msg){
kafkaTemplate.send("bigdata",msg);
return "hello";
}
}
5.2.4 编写Consumer
将Consumer定为组件,这样就能在后台一直运行,一直监听消息
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class KafkaConsumer {
//指定监听主题
@KafkaListener(topics = "bigdata")
public void listen(ConsumerRecord<?,?> record) throws Exception{
System.out.println("topic: "+record.topic()+" partiation: "+record.partition()+" value: "+record.value());
}
}
搭建完成后访问 /kafka/send 接口就能够看到消费信息
六:连通Canal、Kafka、Mysql
现在我们的业务项目已经和Canal以及Kafka连通了,而且我们的已经成功从Mysql监听到了sql的动向,因此去修改CanalClient中的executeQueueSql方法:
@Resource
private KafkaTemplate<String,String> kafkaTemplate;
/**
* 模拟执行队列里面的sql语句
*/
public void executeQueueSql() {
int size = SQL_QUEUE.size();
for (int i = 0; i < size; i++) {
String sql = SQL_QUEUE.poll();
//System.out.println("[sql]----> " + sql);
//将sql发送给消息中间件 "bigdata"是自定义的topic
kafkaTemplate.send("bigdata",sql);
}
}
如此,sql语句就能够通过kafka传递给消费者了。消费者拿到之后肯定要去执行sql,因此我们需要一个指定的备份数据库用来使用这些sql插入数据,所以第一步要做的就是先备份一个数据库。
这里我主要存数据的服务器假设运行在192.169.1.132:3306上,那么我再将数据导出把它写进192.169.1.133:3306里,因为canal是只做增量的,不会对已操作过的老数据进行侦听,所以这一步是必须的。
KafkaConsumer
import com.springboot.myweb.service.SqlService;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class KafkaConsumer {
@Autowired
private SqlService sqlService;
//指定监听主题
@KafkaListener(topics = "bigdata")
public void listen(ConsumerRecord<?, ?> record) throws Exception {
// 获取并执行sql
String sql = record.value().toString();
sqlService.execute(sql);
}
}
SqlService
public interface SqlService {
void execute(String sql);
}
SqlServiceImpl
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class SqlServiceImpl implements SqlService {
@Autowired
private SqlMapper sqlMapper;
@Override
public void execute(String sql) {
sqlMapper.execute(sql);
}
}
SqlMapper
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Param;
import org.springframework.stereotype.Repository;
@Repository
public interface SqlMapper extends BaseMapper {
void execute(@Param("sql") String sql);
}
SqlMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.springboot.myweb.mapper.SqlMapper">
<select id="execute" parameterType="java.lang.String">
${sql}
</select>
</mapper>
七:数据可靠性优化
对于上面的演示方法,也仅仅是能够使用Kafka进行数据传输而已,但对于消息是否丢失,消息是否被重复消费等问题上,这就需要进一步进行优化。
生产者端
首先,对于Kafka生产者端,要配置ack应答,这里有三个参数0,1,-1(all),其中,0是不等待broker响应,把消息发过去就不管了,是效率最高但准确率最低的一个参数;1是Kafka默认配置,是指分区的Leader只要能够成功写入消息,就认为成功,但如果leader被选举机制干掉了,那数据还是会丢失;-1是可靠性最高的一个配置,只有等全部的副本和分区成功写入消息之后才会真正应答,这是效率低但可靠性最高的一个配置。
关于retries的配置策略,是指生产者端的重试机制,当生产者端因为网络波动等原因导致数据发断了的时候,等到网络再恢复的时候,生产者会进行一个重新发送的尝试,从而将之前未发成功的数据再发过去。
消费者端
对于消费者端,需要将之前设置的自动提交offset偏移量设置为手动提交偏移量,并且在应答的时候使用ack进行手动应答。关于从何处开始消费,因为canal是增量,因此设置的时候可以是从最晚的开始,在原来的基础上增量。再者,是重复消费的问题,可以将消息设置一个唯一标识然后存储到redis缓存中去,如果我100条数据消费到第50条崩溃了,下次还是从0开始,但前50条已经消费过了,没必要再消费,因此直接带进redis中查,如果没有该标识,说明需要消费,如果有,则就是重复消息。最后,是效率问题,如果上百条消息,每一条都应答,那么系统将浪费大量时间在应答上,十分影响效率,因此可以优化成批处理应答。
yaml中Kafka通用配置
kafka:
bootstrap-servers: 124.71.96.193:9092
producer:
retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送
batch-size: 16384
buffer-memory: 33554432
acks: all
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: test01 #组名
enable-auto-commit: false #关闭自动提交offset
auto-offset-reset: latest
auto-commit-interval: 1000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种
# MANUAL_IMMEDIATE
ack-mode: manual_immediate
7.1 逐条应答
Kafka来一条消息应答一次,逐条应答是数据准确度最高的一种方案,同时也是效率最低的一种方案,因为这样会让Kafka把大量的时间都花费在应答机制上,从而影响效率。
CanalClient
import cn.hutool.core.util.IdUtil;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.net.InetSocketAddress;
import java.util.ArrayList;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
@Component
public class CanalClient {
Logger logger = LoggerFactory.getLogger(CanalClient.class);
//sql队列
private Queue<String> SQL_QUEUE = new ConcurrentLinkedQueue<>();
@Resource
private KafkaTemplate<Object, String> kafkaTemplate;
/**
* canal入库方法
*/
public void run() {
/*master服务器地址,以及开启的端口号,实例名instance.properties文件中不修改这用这个默认的,用户名密码使用远程连接账号的,同前配置文件*/
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("114.115.179.10",
9200), "example", "", "");
int batchSize = 1000;
try {
while (true) {
logger.info("-------------canal开始连接-------------");
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
} catch (Exception e) {
logger.info("-------------canal连接失败,五分钟后尝试重新连接-------------");
try {
Thread.sleep(300000);
} catch (InterruptedException e1) {
logger.error(e1.getMessage());
}
}
logger.info("-------------canal连接成功-------------");
break;
}
while (true) try {
/*从master拉取数据batchSize条记录*/
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
Thread.sleep(10000);
} else {
dataHandle(message.getEntries());
}
/*提交ack确认*/
connector.ack(batchId);
/*设置队列sql语句执行最大值*/
if (SQL_QUEUE.size() >= 1) {
executeQueueSql();
}
} catch (Exception e) {
e.printStackTrace();
logger.error("canal入库方法" + e.getMessage());
}
} finally {
connector.disconnect();
}
}
/**
* 模拟执行队列里面的sql语句
*/
public void executeQueueSql() {
for (int i = 0; i < SQL_QUEUE.size(); i++) {
String sql = IdUtil.simpleUUID() +"@"+ SQL_QUEUE.poll();
//将sql发送给消息中间件
kafkaTemplate.send("bigdata",sql.trim());
}
}
/**
* 数据处理
*
* @param entrys
*/
private void dataHandle(List<Entry> entrys) throws
InvalidProtocolBufferException {
for (Entry entry : entrys) {
if (EntryType.ROWDATA == entry.getEntryType()) {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
EventType eventType = rowChange.getEventType();
if (eventType == EventType.DELETE) {
saveDeleteSql(entry);
} else if (eventType == EventType.UPDATE) {
saveUpdateSql(entry);
} else if (eventType == EventType.INSERT) {
saveInsertSql(entry);
}
}
}
}
/**
* 保存更新语句
*
* @param entry
*/
private void saveUpdateSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> newColumnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("update " +
entry.getHeader().getTableName() + " set ");
for (int i = 0; i < newColumnList.size(); i++) {
sql.append(" " + newColumnList.get(i).getName()
+ " = '" + newColumnList.get(i).getValue() + "'");
if (i != newColumnList.size() - 1) {
sql.append(",");
}
}
sql.append(" where ");
List<Column> oldColumnList = rowData.getBeforeColumnsList();
for (Column column : oldColumnList) {
if (column.getIsKey()) {
//暂时只支持单一主键
sql.append(column.getName() + "= '" + column.getValue() +"'");
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* 保存删除语句
*
* @param entry
*/
private void saveDeleteSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> columnList = rowData.getBeforeColumnsList();
StringBuffer sql = new StringBuffer("delete from " +
entry.getHeader().getTableName() + " where ");
for (Column column : columnList) {
if (column.getIsKey()) {
//暂时只支持单一主键
sql.append(column.getName() + "= '" + column.getValue() +"'");
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* 保存插入语句
*
* @param entry
*/
private void saveInsertSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> columnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("insert into " +
entry.getHeader().getTableName() + " (");
for (int i = 0; i < columnList.size(); i++) {
sql.append(columnList.get(i).getName());
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(") VALUES (");
for (int i = 0; i < columnList.size(); i++) {
sql.append("'" + columnList.get(i).getValue() + "'");
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(")");
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
}
消费者端
import com.springboot.myweb.service.SqlService;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
@Component
public class KafkaConsumer {
@Autowired
private SqlService sqlService;
@Resource
private KafkaTemplate<Object, String> kafkaTemplate;
/**
* 主要消费者
*
* @param record
* @param ack
* @throws Exception
*/
@KafkaListener(topics = "bigdata")
public void listen(ConsumerRecord<?, ?> record, Acknowledgment ack) throws Exception {
String preSql = record.value().toString();
if (preSql == null) {
return;
}
// 分割字符串
Integer integer = startChar(preSql, "@");
String sql = preSql.substring(integer + 1);// 获取sql
// 如果成功执行了就回答
if (sqlService.execute(sql)) {
ack.acknowledge(); // 手动回答
}
}
/**
* 用来处理失败消息的消费者
*
* @param record
* @param ack
* @throws Exception
*/
@KafkaListener(topics = "execFailMessage")
public void listenFail(ConsumerRecord<?, ?> record, Acknowledgment ack) throws Exception {
// 获取并执行sql
String sql = record.value().toString();
// 如果执行成功的次数累计到n次,则提交手动应答
if (sqlService.execute(sql)) {
ack.acknowledge(); //应答
} else {
// 如果处理失败,将消息发送给备份topic,用来其他消费者专门处理这些失败的业务
kafkaTemplate.send("execFailMessage", sql);
}
}
// 寻找字符第一次出现的下标
public static Integer startChar(String str,String specialChar){
Matcher matcher= Pattern.compile(specialChar).matcher(str);
if(matcher.find()){
Integer start = matcher.start();
return start;
}
return null;
}
}
7.2 批量应答Redis方案
CanalClient
import cn.hutool.core.util.IdUtil;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.net.InetSocketAddress;
import java.util.ArrayList;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
@Component
public class CanalClient {
Logger logger = LoggerFactory.getLogger(CanalClient.class);
//sql队列
private Queue<String> SQL_QUEUE = new ConcurrentLinkedQueue<>();
@Resource
private KafkaTemplate<Object, String> kafkaTemplate;
/**
* canal入库方法
*/
public void run() {
/*master服务器地址,以及开启的端口号,实例名instance.properties文件中不修改这用这个默认的,用户名密码使用远程连接账号的,同前配置文件*/
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("114.115.179.10",
9200), "example", "", "");
int batchSize = 1000;
try {
while (true) {
logger.info("-------------canal开始连接-------------");
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
} catch (Exception e) {
logger.info("-------------canal连接失败,五分钟后尝试重新连接-------------");
try {
Thread.sleep(300000);
} catch (InterruptedException e1) {
logger.error(e1.getMessage());
}
}
logger.info("-------------canal连接成功-------------");
break;
}
while (true) try {
/*从master拉取数据batchSize条记录*/
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
Thread.sleep(10000);
} else {
dataHandle(message.getEntries());
}
/*提交ack确认*/
connector.ack(batchId);
/*设置队列sql语句执行最大值*/
if (SQL_QUEUE.size() >= 1) {
executeQueueSql();
}
} catch (Exception e) {
e.printStackTrace();
logger.error("canal入库方法" + e.getMessage());
}
} finally {
connector.disconnect();
}
}
/**
* 模拟执行队列里面的sql语句
*/
public void executeQueueSql() {
for (int i = 0; i < SQL_QUEUE.size(); i++) {
String sql = IdUtil.simpleUUID() +"@"+ SQL_QUEUE.poll();
//将sql发送给消息中间件
kafkaTemplate.send("bigdata",sql.trim());
}
}
/**
* 数据处理
*
* @param entrys
*/
private void dataHandle(List<Entry> entrys) throws
InvalidProtocolBufferException {
for (Entry entry : entrys) {
if (EntryType.ROWDATA == entry.getEntryType()) {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
EventType eventType = rowChange.getEventType();
if (eventType == EventType.DELETE) {
saveDeleteSql(entry);
} else if (eventType == EventType.UPDATE) {
saveUpdateSql(entry);
} else if (eventType == EventType.INSERT) {
saveInsertSql(entry);
}
}
}
}
/**
* 保存更新语句
*
* @param entry
*/
private void saveUpdateSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> newColumnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("update " +
entry.getHeader().getTableName() + " set ");
for (int i = 0; i < newColumnList.size(); i++) {
sql.append(" " + newColumnList.get(i).getName()
+ " = '" + newColumnList.get(i).getValue() + "'");
if (i != newColumnList.size() - 1) {
sql.append(",");
}
}
sql.append(" where ");
List<Column> oldColumnList = rowData.getBeforeColumnsList();
for (Column column : oldColumnList) {
if (column.getIsKey()) {
//暂时只支持单一主键
sql.append(column.getName() + "= '" + column.getValue() +"'");
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* 保存删除语句
*
* @param entry
*/
private void saveDeleteSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> columnList = rowData.getBeforeColumnsList();
StringBuffer sql = new StringBuffer("delete from " +
entry.getHeader().getTableName() + " where ");
for (Column column : columnList) {
if (column.getIsKey()) {
//暂时只支持单一主键
sql.append(column.getName() + "= '" + column.getValue() +"'");
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* 保存插入语句
*
* @param entry
*/
private void saveInsertSql(Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<Column> columnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("insert into " +
entry.getHeader().getTableName() + " (");
for (int i = 0; i < columnList.size(); i++) {
sql.append(columnList.get(i).getName());
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(") VALUES (");
for (int i = 0; i < columnList.size(); i++) {
sql.append("'" + columnList.get(i).getValue() + "'");
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(")");
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
}
消费者
import com.springboot.myweb.service.SqlService;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
@Component
public class KafkaConsumer {
// 计数器
private static AtomicInteger NUMBER = new AtomicInteger(0);
// 最大累加次数
private static Integer MAX = 5;
@Autowired
private SqlService sqlService;
@Autowired
private RedisTemplate redisTemplate;
@Resource
private KafkaTemplate<Object, String> kafkaTemplate;
/**
* 主要消费者
*
* @param record
* @param ack
* @throws Exception
*/
@KafkaListener(topics = "bigdata")
public void listen(ConsumerRecord<?, ?> record, Acknowledgment ack) throws Exception {
String preSql = record.value().toString();
if (preSql == null) {
return;
}
// 分割字符串
Integer integer = startChar(preSql, "@");
String id = preSql.substring(0, integer);// uniqueKey
String sql = preSql.substring(integer+1);// 获取sql
System.out.println("消费 " + sql);
//如果该key在缓存中存在就放过,说明已经执行过一次
if (!redisTemplate.opsForSet().isMember("hashKey", id)) {
// 如果执行成功的次数累计到n次,则提交手动应答
if (sqlService.execute(sql)) {
redisTemplate.opsForSet().add("hashKey", id, 1, TimeUnit.HOURS);//添加到hashKey
NUMBER.getAndIncrement();//递增
if (NUMBER.get() == MAX) {
ack.acknowledge(); // 手动回答
NUMBER.set(0); //计数器归零
}
} else {
// 如果处理失败,将消息发送给备份topic,用来其他消费者专门处理这些失败的业务
kafkaTemplate.send("execFailMessage", sql);
}
}
}
/**
* 用来处理失败消息的消费者
*
* @param record
* @param ack
* @throws Exception
*/
@KafkaListener(topics = "execFailMessage")
public void listenFail(ConsumerRecord<?, ?> record, Acknowledgment ack) throws Exception {
// 获取并执行sql
String sql = record.value().toString();
// 如果执行成功的次数累计到n次,则提交手动应答
if (sqlService.execute(sql)) {
ack.acknowledge(); //应答
} else {
// 如果处理失败,将消息发送给备份topic,用来其他消费者专门处理这些失败的业务
kafkaTemplate.send("execFailMessage", sql);
}
}
// 寻找字符第一次出现的下标
public static Integer startChar(String str,String specialChar){
Matcher matcher= Pattern.compile(specialChar).matcher(str);
if(matcher.find()){
Integer start = matcher.start();
return start;
}
return null;
}
}
7.3 批量应答Map方案
生产者相同
消费者
import com.springboot.myweb.service.SqlService;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
@Component
public class KafkaConsumer {
// 计数器
private static AtomicInteger NUMBER = new AtomicInteger(0);
// 最大累加次数
private static Integer MAX = 5;
@Autowired
private SqlService sqlService;
// 缓存map
public static Map<String,String> MAP = new ConcurrentHashMap<>();
@Resource
private KafkaTemplate<Object, String> kafkaTemplate;
/**
* 主要消费者
*
* @param record
* @param ack
* @throws Exception
*/
@KafkaListener(topics = "bigdata")
public void listen(ConsumerRecord<?, ?> record, Acknowledgment ack) throws Exception {
String preSql = record.value().toString();
if (preSql == null) {
return;
}
// 分割字符串
Integer integer = startChar(preSql, "@");
String id = preSql.substring(0, integer);// uniqueKey
String sql = preSql.substring(integer+1);// 获取sql
//System.out.println("消费 " + sql);
//如果该key在缓存中存在就放过,说明已经执行过一次
if (MAP.get(id) == null) {
// 如果执行成功的次数累计到n次,则提交手动应答
if (sqlService.execute(sql)) {
MAP.put(id,sql);// 写入缓存
NUMBER.getAndIncrement();//递增
if (NUMBER.get() == MAX) {
ack.acknowledge(); // 手动回答
MAP.clear(); // 清空缓存
NUMBER.set(0); //计数器归零
}
} else {
// 如果处理失败,将消息发送给备份topic,用来其他消费者专门处理这些失败的业务
kafkaTemplate.send("execFailMessage", sql);
}
}
}
/**
* 用来处理失败消息的消费者
*
* @param record
* @param ack
* @throws Exception
*/
@KafkaListener(topics = "execFailMessage")
public void listenFail(ConsumerRecord<?, ?> record, Acknowledgment ack) throws Exception {
// 获取并执行sql
String sql = record.value().toString();
// 如果执行成功的次数累计到n次,则提交手动应答
if (sqlService.execute(sql)) {
ack.acknowledge(); //应答
} else {
// 如果处理失败,将消息发送给备份topic,用来其他消费者专门处理这些失败的业务
kafkaTemplate.send("execFailMessage", sql);
}
}
// 寻找字符第一次出现的下标
public static Integer startChar(String str,String specialChar){
Matcher matcher= Pattern.compile(specialChar).matcher(str);
if(matcher.find()){
Integer start = matcher.start();
return start;
}
return null;
}
//定时任务,每隔15分钟清除一次MAP缓存
@Scheduled(cron = "0 */15 * * * ?")
public void clearMap() {
if (MAP.size() > 0) {
MAP.clear();
}
}
}
关于清空map缓存,我们来一个定时任务
@SpringBootApplication
@MapperScan("com.springboot.myweb.mapper")
@EnableScheduling
public class WebApplication {
public static void main(String[] args) {
SpringApplication.run(WebApplication.class, args);
}
}
7.4 对指定表进行过滤
CanalClient修改如下
@Component
public class CanalClient {
....
// 记录不需要备份的表名
private static List<String> list = new ArrayList(){{
add("user");
add("table");
}};
.....
/**
* 模拟执行队列里面的sql语句
*/
public void executeQueueSql() {
for (int i = 0; i < SQL_QUEUE.size(); i++) {
// 如果该sql执行的表在过滤名单中则跳过
if(isFilterList(SQL_QUEUE.poll().trim())){
continue;
}
String sql = IdUtil.simpleUUID() +"@"+ SQL_QUEUE.poll();
//将sql发送给消息中间件
kafkaTemplate.send("bigdata",sql.trim());
}
}
/**
* 检验表是否需要被过滤掉
* @param sql
* @return
*/
public boolean isFilterList(String sql){
String[] s = sql.split(" ");
String ddl = s[0]; //取到语句头
if(ddl.equals("update")){
String tableName = s[1];// 得到表名
if(list.contains(tableName)){
return true;
}
}else{
// 删除和插入
String tableName = s[2];// 得到表名
if(list.contains(tableName)){
return true;
}
}
return false;
}
}
{{ cmt.username }}
{{ cmt.content }}
{{ cmt.commentDate | formatDate('YYYY.MM.DD hh:mm') }}